
Retour d'expérience sur un projet R&D concret : de l'échec initial au succès en production
Imaginez cette situation : vos clients doivent transmettre des justificatifs pour bénéficier d’un service complémentaire. Factures, attestations, certificats… Ces documents arrivent dans tous les formats possibles – PDF scannés, photos prises au téléphone, captures d’écran – et contiennent des informations cruciales à vérifier : nom du demandeur, date, entreprise, tampon, signature, codes produit.
Le défi ? Automatiser cette validation qui prenait un temps considérable à vos équipes, tout en maintenant un niveau de fiabilité irréprochable.
Le problème ? Notre première tentative d’automatisation par IA n’avait pas donné les résultats escomptés.
Plutôt que d’abandonner, nous avons lancé un projet de R&D méthodique pour comprendre pourquoi et comment améliorer notre approche.
Notre projet R&D d'IA pour la validation de documents en 6 étapes
Étape 1 : Créer la "vérité de référence" (Ground Truth)
Avant de pouvoir mesurer les performances de notre IA, nous devions établir ce qu’est une « bonne réponse ». C’est le principe de la ground truth, littéralement « la vérité terrain ».
Concrètement : un expert humain a analysé manuellement une trentaine de documents représentatifs, en documentant scrupuleusement pour chacun :
✅ Nom du demandeur présent ? Absent ?
✅ Date du document visible ? Illisible ?
✅ Entreprise mentionnée ? Manquante ?
✅ Tampon officiel présent ? Absent ?
✅ Signature identifiable ? Non détectée ?
✅ Code produit correct ? Erroné ?
Cette étape peut sembler fastidieuse, mais elle est absolument critique. Sans cette référence fiable, impossible de savoir si notre IA progresse ou régresse !
Étape 2 : Concevoir et paramétrer différentes approches
Plutôt que de miser sur une seule solution, nous avons développé deux pipelines d’analyse distincts, chacun pouvant combiner plusieurs modèles d’IA spécialisés.
Chaque pipeline a été testé manuellement sur nos documents de référence, avec différents paramètres et combinaisons de modèles, pour identifier les configurations les plus prometteuses.
Étape 3 : Exécuter les tests à grande échelle
Une fois nos pipelines configurés, nous les avons fait tourner sur l’ensemble de nos 30 documents de référence. Tous les résultats ont été automatiquement stockés en base de données pour analyse comparative.
Étape 4 : Comparer avec la réalité
Vient alors le moment de vérité : confronter les prédictions de nos IA avec la ground truth établie par l’expert humain. Pour chaque document et chaque information recherchée, nous savons maintenant si notre système a vu juste ou s’est trompé.
Étape 5 : Analyser les performances avec des indicateurs métier
Pour évaluer objectivement nos résultats, nous utilisons quatre indicateurs classiques en intelligence artificielle. Voici ce qu’ils signifient concrètement :
Accuracy (Exactitude)
« Sur 100 vérifications, combien sont correctes ? »
Si notre IA examine 100 éléments et en identifie correctement 85, l’accuracy est de 85%. C’est l’indicateur le plus intuitif, mais pas toujours le plus pertinent.
Precision (Précision)
« Quand l’IA dit ‘présent’, à quelle fréquence a-t-elle raison ? »
Si l’IA détecte 20 tampons et que 18 sont effectivement présents, la précision est de 90%. Cet indicateur mesure la fiabilité des détections positives.
Recall (Rappel)
« Sur tous les éléments réellement présents, combien l’IA en a-t-elle trouvés ? »
Si 25 documents contiennent effectivement un tampon et que l’IA en détecte 20, le rappel est de 80%. Cet indicateur mesure la capacité à ne rien manquer d’important.
F1-Score
« Quel est l’équilibre global entre précision et rappel ? »
Le F1-score combine précision et rappel en une seule métrique. Plus il est proche de 100%, mieux c’est. C’est souvent l’indicateur de référence pour comparer différentes approches.
Étape 6 : Comparer et analyser les résultats
Nous avons calculé ces indicateurs selon deux angles :
Vision globale par pipeline
Quel pipeline obtient les meilleures performances générales ? Pipeline A ou Pipeline B ?
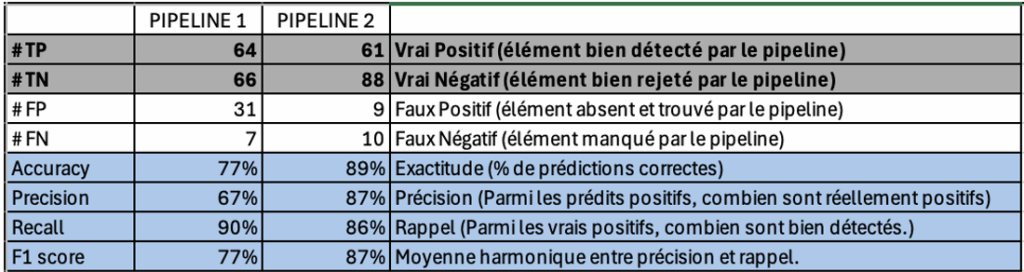
Vision détaillée par type d'information
Pour chaque élément recherché (nom, date, tampon, etc.), quel pipeline est le plus fiable ? Quels sont nos points faibles à surveiller ?
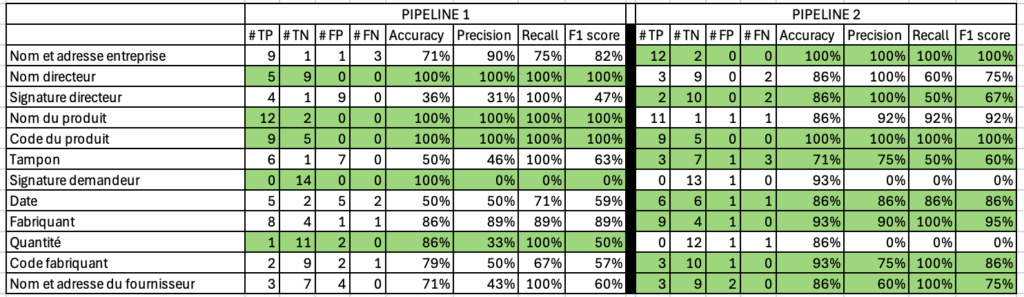
Cette double analyse nous a permis de choisir la meilleure configuration et d’identifier les zones nécessitant une attention particulière en production.
Résultat : Mission accomplie !
Grâce à cette démarche méthodique, nous avons réussi à construire et valider un pipeline suffisamment performant pour le déployer en production.
Notre système automatise désormais la première étape de validation des justificatifs, avec un niveau de conformité qui nous permet de traiter la majorité des cas en autonomie. Nous gardons toutefois un œil attentif sur un ou deux aspects spécifiques identifiés lors de notre analyse, garantissant ainsi une qualité de service optimale.
Le gain ? Un traitement plus rapide pour vos clients, moins de tâches répétitives pour vos équipes, et une fiabilité mesurée scientifiquement.
Votre projet IA vous pose des défis ?
Cette approche méthodique – de l’analyse du problème jusqu’à la validation en production – illustre notre façon de concevoir l’intelligence artificielle au service de votre relation client.
Une idée ? Un projet ? Faites-nous signe !
Chez faibrik, nous transformons vos défis techniques en solutions concrètes, avec la rigueur d’une démarche scientifique et la simplicité d’un service qui fonctionne.